Listen to this article (AI-generated narration)
When I relaunched this website, I had a clear vision for what it would be: a place where all my thoughts, opinions, and deep dives would live. Every essay would be a response to a question I get asked frequently, so instead of repeating myself, I could share a link. Write it once, reference it forever.
That worked well for the big questions. But not every question needed a 3,000-word essay. Sometimes someone wanted to know what I think about a specific framework, or how I approach a particular problem, or what my stance is on some debate in tech. The answer might be buried in paragraph fourteen of a post they’d have to read in full to find. Or worse, it might not be in any essay at all, something I said once in a tweet or mentioned in passing somewhere.
And then there’s the archive that disappeared. I spent 15 years on Twitter. Thousands of tweets about software engineering, mentoring, things I was building, opinions on tech trends, random thoughts at 2am. When I left social media, all of that vanished from public view. Not deleted (I had my data export) but gone. A decade and a half of my thinking, inaccessible to anyone, including me most of the time.
I kept coming back to the same idea: what if this website could answer questions? Not through a search bar that returns a list of posts, but conversationally, the way I would if you asked me in person. Something that could pull from everything I’ve written and said, whether it’s a blog post from last month or a tweet from 2012, and respond as if I were there.
That’s the “Ask Me Anything” feature you can see in the bottom-right corner of this page. It’s a chatbot that searches through all my blog posts and 15 years of my tweets to find relevant context, then uses Anthropic’s Claude, a large language model, to generate a response in my voice. The responses stream in real-time, and the conversation persists as you navigate between pages.
I’d been using AI tools more and more in my day-to-day work: coding assistants, large language models for research, the usual. But I had never built anything close to a chatbot. I knew it was possible to get most of the way there by integrating existing off-the-shelf tools; there are platforms that will handle the entire pipeline for you. But that wasn’t the point. I wanted to challenge myself and go a level lower. Figure out all the individual pieces (embeddings, vector search, retrieval, streaming, prompt engineering) and wire them together myself, with as much control as possible over the components and dependencies.
The constraint I gave myself made it more interesting: make it all work on my existing stack. An API server with SQLite, running on a single server. No Postgres. No Pinecone. No Redis. SQLite doing things SQLite wasn’t supposed to do.
The starting point
Before the chatbot, the site already had a fair amount going on. The stack looked like this:
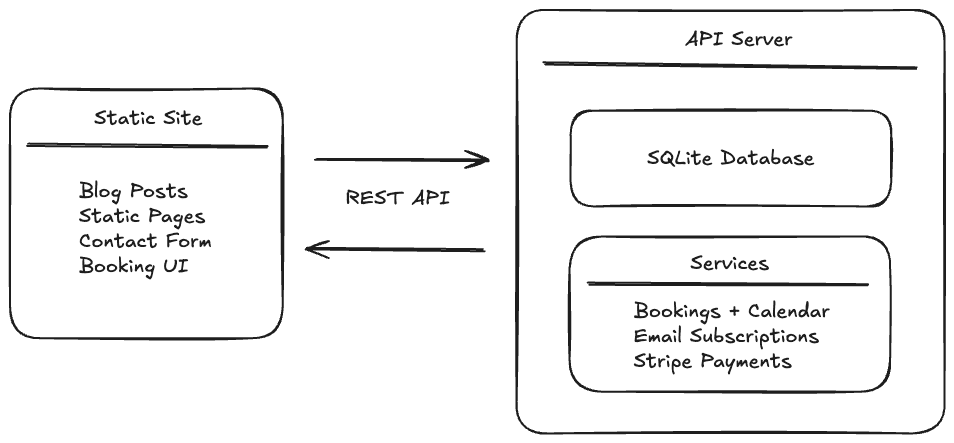
This was a SQLite-only backend. Background jobs, caching, continuous database replication, all backed by SQLite. No Postgres, no Redis, no external services beyond the APIs I was calling (Stripe, Google Calendar, Gmail). The entire application ran as a single Docker container on one server.
This was the context that shaped every decision in the chatbot build. I didn’t want to introduce a vector database like Pinecone or switch to Postgres for pgvector. The constraint was: whatever I build has to fit into this existing architecture.
Planning it out
Before writing any code, I needed to understand what building something like this required. I’d never built a chatbot before. So I started the way I start any project where I’m learning something new: define the end goal, then work backwards to figure out the minimum set of pieces needed to get there.
The goal was clear: a chatbot on my website that could answer questions about me using my own writing as source material. Working backwards from that, I broke the problem into questions:
How does the chatbot know what I’ve written? It needs my content — blog posts, tweets — stored somewhere searchable. Simple enough.
How does it find the relevant content for a given question? This is where things get interesting. A basic keyword search wouldn’t cut it. If someone asks “What’s your take on writing clean code?”, they should find a tweet where I said “readable code matters more than clever code” — even though the words don’t overlap at all. What I needed was semantic search: search based on meaning, not just matching words.
How does semantic search work? The core idea is intuitive. You take a piece of text and convert it into a list of numbers, hundreds or thousands of them, that represent the meaning of that text. These numerical representations are called embeddings, and the list of numbers is a vector. Texts that mean similar things end up with similar vectors, even if they use different words. To search, you convert the user’s question into a vector too, then find the stored vectors that are closest to it. “Closest” is measured using something called cosine similarity, which measures how much two vectors point in the same direction.
Where do the vectors live? Typically in a specialized vector database like Pinecone or Weaviate. But I was already running SQLite for everything else, so I went looking for a way to keep vectors there too — and found a SQLite extension that could handle it.
How does it generate a human-sounding answer from the retrieved content? This is where a large language model (LLM) comes in: AI models like Claude or GPT that can read text and generate natural-sounding responses. The idea is to find the most relevant passages from my writing, feed them to the LLM as context, and have it synthesize a conversational answer grounded in what I’ve said. The amount of text you can feed to an LLM at once is called its context window, how much it can “read” in a single request.
This whole approach has a name: retrieval-augmented generation, or RAG. You retrieve relevant content first, then use it to augment the generation of a response. Instead of the LLM making things up from its general training data, it’s answering based on specific source material you provide.
That gave me the component list: a content pipeline, an embedding service, a vector store, and an LLM integration. I sketched out how data would flow through the system:
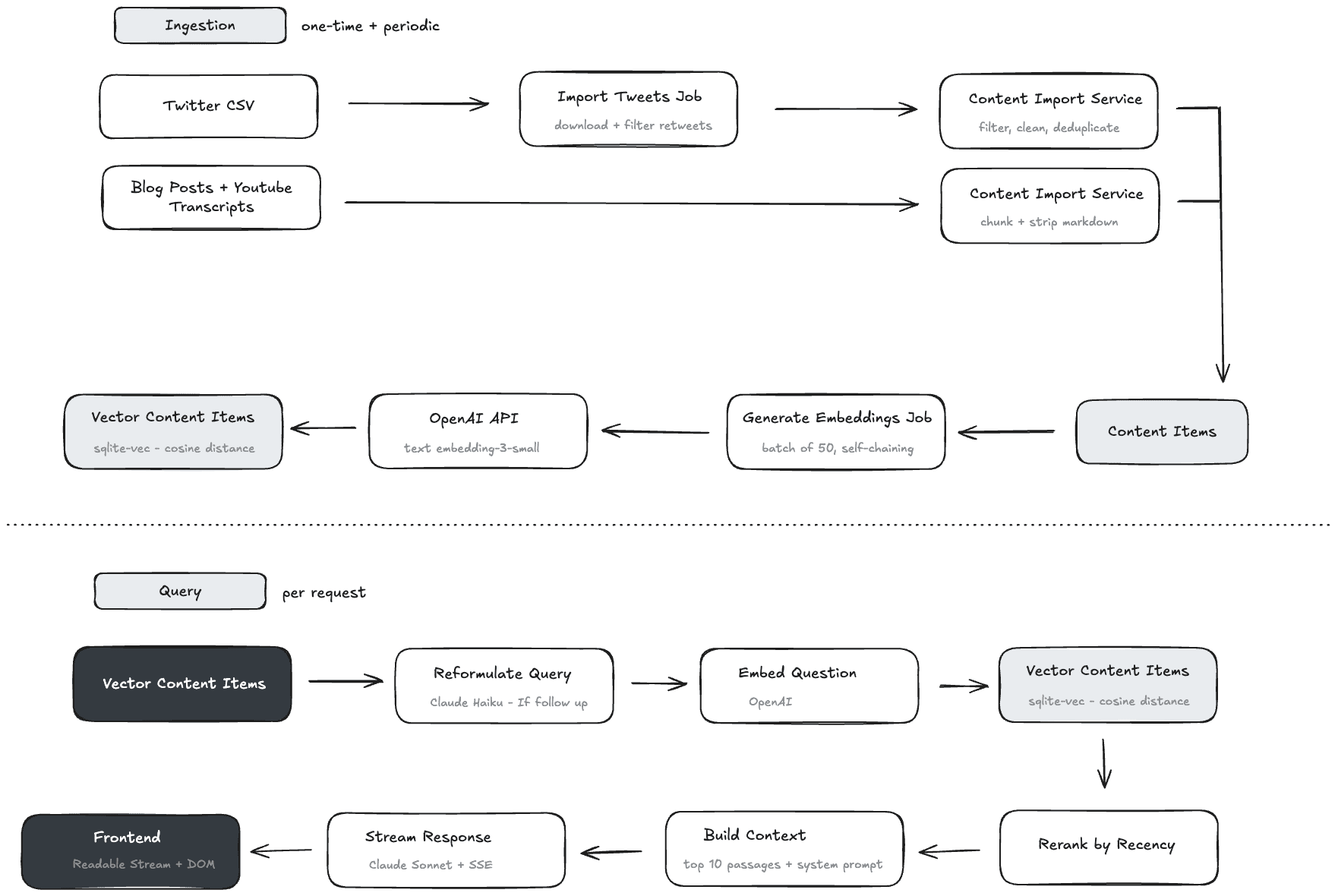
With this map in hand, I could see which pieces I needed to learn (embedding generation, vector search, streaming responses) and which I already knew (data models, background jobs, JavaScript fetch). None of the individual pieces were that complex. The challenge was wiring them together correctly.
I also made a key architectural decision at this stage: everything stays in SQLite. No Postgres for the main database, no Pinecone for vectors, no Redis for job queues. One database engine, one process, one server. This constraint simplified the entire system and meant I could focus on the RAG logic instead of infrastructure.
The architecture
The system had three main phases:
1. Content ingestion — Import tweets from a CSV file and blog posts from markdown files, chunk them into searchable passages, and store them in SQLite.
2. Embedding generation — Send each content chunk to OpenAI’s text-embedding-3-small model to get a 1536-dimensional vector — a list of 1,536 numbers representing the meaning of that text — then store that vector in a SQLite virtual table for similarity search.
3. Query and response — When a user asks a question, embed the question, find the most similar content chunks via vector search, build a context window from those chunks, and stream a response from Claude.
The entire pipeline ran inside a single application. No microservices, no external vector databases, no message queues. Background jobs handled the heavy lifting (embedding generation and tweet imports), and everything persisted to SQLite files that got continuously replicated offsite.
Vector search in SQLite
The most unconventional part of this setup was using SQLite for vector similarity search. Most RAG tutorials point you toward Pinecone, Weaviate, or pgvector. I didn’t want to add another database to my stack. I was running SQLite for everything else (application data, background job queues, caching) so I went looking for a way to keep vectors there too.
sqlite-vec is a SQLite extension that adds vector search capabilities through virtual tables. The distance_metric=cosine tells it to use cosine similarity, the same “how much do these vectors point in the same direction?” measurement I mentioned earlier. You create a table like this:
CREATE VIRTUAL TABLE IF NOT EXISTS vec_content_items USING vec0(
embedding float[1536] distance_metric=cosine
);
Then you can find the closest vectors, the “k nearest neighbors” where k is however many results you want, with a query that looks almost too simple:
SELECT rowid, distance
FROM vec_content_items
WHERE embedding MATCH ?
AND k = 10
ORDER BY distance
The rowid maps back to your regular content_items table, so you get the full content and metadata through a standard database lookup. The embedding is passed as a packed binary float array. It’s not going to beat a purpose-built vector database at scale, but for my use case — tens of thousands of content chunks — it was more than fast enough, and I didn’t have to manage another service.
Getting sqlite-vec working required some careful initialization. The extension needed to be loaded on every new database connection, which meant hooking into the connection lifecycle. I wrote an initialization hook that runs every time a new connection opens from the pool: it enables extension loading (which SQLite disables by default for security), loads the sqlite-vec binary, then disables extension loading again.
The virtual table itself was created at application startup rather than in a database migration, since vec0 tables aren’t managed by standard schema systems:
on application startup:
reconnect database pool // ensure fresh connections have the extension
db = get raw database connection
db.execute("SELECT vec_version()") // verify extension is loaded
db.execute("""
CREATE VIRTUAL TABLE IF NOT EXISTS vec_content_items USING vec0(
embedding float[1536] distance_metric=cosine
);
""")
On the model side, I wrapped the raw SQL for storing and searching embeddings behind clean methods:
function store_embedding(content_item, embedding_vector):
db = get raw database connection
db.execute(
"INSERT OR REPLACE INTO vec_content_items(rowid, embedding) VALUES (?, ?)",
[content_item.id, pack_as_floats(embedding_vector)]
)
content_item.update(embedded: true)
function search_similar(query_embedding, limit = 10):
db = get raw database connection
rows = db.execute("""
SELECT rowid, distance
FROM vec_content_items
WHERE embedding MATCH ?
AND k = ?
ORDER BY distance
""", [pack_as_floats(query_embedding), limit])
ids_with_distance = rows.map(row => [row.rowid, row.distance])
items = fetch content_items WHERE id IN ids_with_distance.ids
return ids_with_distance.map(id, distance =>
{ content_item: items[id], distance: distance }
)
The pack_as_floats call converts an array of floats into the packed binary format that sqlite-vec expects. On the query side, the result comes back as rowid/distance pairs, which get joined back to the full content item records through a standard WHERE id IN (...) query.
Chunking blog posts for better retrieval
One thing I learned quickly: you can’t just throw an entire 3,000-word blog post into a single embedding and expect good search results. The embedding becomes a blurry average of everything in the post, and specific passages get lost.
The solution was chunking: splitting each post into smaller passages. I targeted roughly 500 tokens per chunk, which worked out to about 2,000 characters. (A “token” is the unit that language models use to process text, roughly three-quarters of a word in English. “Software engineering” is two words but three tokens.) Each chunk included a 200-character overlap with the one before it, so ideas spanning a chunk boundary didn’t get cut in half.
CHUNK_MAX_CHARS = 2000
CHUNK_OVERLAP_CHARS = 200
function chunk_text(text):
if text.length <= CHUNK_MAX_CHARS:
return [text]
chunks = []
paragraphs = text.split_on_double_newlines()
current_chunk = ""
for each paragraph in paragraphs:
if current_chunk.length + paragraph.length + 2 > CHUNK_MAX_CHARS and current_chunk is not empty:
chunks.append(current_chunk.strip())
// Keep overlap from end of previous chunk
overlap_start = max(current_chunk.length - CHUNK_OVERLAP_CHARS, 0)
current_chunk = current_chunk[overlap_start..] + "\n\n" + paragraph
else:
if current_chunk is not empty: current_chunk += "\n\n"
current_chunk += paragraph
chunks.append(current_chunk.strip())
return chunks
The chunking algorithm splits on paragraph boundaries first, which keeps logical units together. Each chunk got the post title prepended for context — the first chunk got “Title\n\ncontent” and subsequent chunks got “Title (continued)\n\ncontent”. This way, even a chunk from the middle of a post carried enough context for the embedding model to understand what it’s about.
Before chunking, the markdown formatting got stripped. Headers, links, images, code blocks, bold/italic markers, all removed. The embedding model doesn’t need to know that something was bold; it needs the semantic content.
function strip_markdown(text):
text = text
.replace_regex(/^#+\s+/, "") // Headers
.replace_regex(/\[text\]\(url\)/, "text") // Links → just the text
.replace_regex(/!\[alt\]\(url\)/, "") // Images → removed
.replace_regex(/bold and italic markers/, "plain") // Bold/italic → plain
.replace_regex(/code spans and blocks/, "") // Code → removed
.replace_regex(/^>\s+/, "") // Blockquotes
.replace_regex(/^[-*+]\s+/, "") // List markers
.replace_regex(/^\d+\.\s+/, "") // Numbered lists
.replace_regex(/\n{3,}/, "\n\n") // Collapse whitespace
.strip()
return text
The import method tied it all together: parse front matter, clean the body, chunk it, and upsert each chunk as a ContentItem with the title prepended:
function import_blog_post(file_path):
raw = read_file(file_path)
front_matter, body = parse_front_matter(raw)
title = front_matter["title"]
slug = extract_slug(file_path) // strip date prefix and .md extension
clean_body = strip_markdown(body)
chunks = chunk_text(clean_body)
for index, chunk in enumerate(chunks):
source_id = slug + "#" + index if chunks.length > 1, else slug
content_with_context = if index == 0:
title + "\n\n" + chunk
else:
title + " (continued)" + "\n\n" + chunk
item = find_or_create content_item where source_type = "blog_post" and source_id = source_id
if item is new or item.content has changed:
item.content = content_with_context
item.embedded = false
item.save()
The find-or-create pattern with a content-changed check made the import idempotent: running it again only re-embedded posts whose content changed.
15 years of tweets
The other content source was my Twitter archive, about 69,000 tweets spanning 15 years. Getting them into the system was its own adventure.
The CSV file was 15 megabytes. My first attempt was uploading it through the browser and processing it on the backend. That didn’t work. The request would time out long before the backend finished processing 69,000 rows. My second attempt was uploading the file and processing it synchronously in the controller. Same problem, the request took too long.
The solution was separating the upload from the processing. I uploaded the CSV to cloud storage from my terminal, then triggered a background job via an admin API endpoint that downloaded it and processed it.
background job ImportTweetsJob:
function perform(storage_key = "imports/tweets.csv"):
temp_path = generate_temp_file_path("tweets_import.csv")
download_from_cloud_storage(key: storage_key, destination: temp_path)
csv_content = read_file(temp_path)
count = content_import_service.import_tweets_csv(csv_content)
if count > 0:
enqueue GenerateEmbeddingsJob
finally:
delete_file(temp_path) if temp_path exists
Not every tweet was worth embedding. The import service filtered out retweets (they start with “RT @”) and very short tweets (under 20 characters after stripping URLs). What remained was the original content: my thoughts and opinions.
function import_tweets_csv(csv_content):
rows = parse_csv(csv_content, headers: true)
imported = 0
for each row in rows:
text = row["full_text"] or row["text"]
skip if text is blank
skip if text starts with "RT @"
clean_text = remove_urls(text).strip()
skip if clean_text.length < 20
item = find_or_create content_item where source_type = "tweet"
and source_id = row["tweet_id"] or row["id"]
if item is new or item.content has changed:
item.content = text
item.embedded = false
item.save()
imported += 1
return imported
The import was idempotent, so running it multiple times only processed new or changed tweets.
The embedding pipeline
Once content was imported, embeddings needed to be generated. This happened in a self-chaining background job that processed 50 items at a time.
background job GenerateEmbeddingsJob:
BATCH_SIZE = 50
function perform():
items = query content_items where embedded = false, limit BATCH_SIZE
return if items is empty
service = new EmbeddingService()
texts = items.map(item => item.content)
embeddings = service.embed_batch(texts)
for each item, embedding in zip(items, embeddings):
item.store_embedding(embedding)
remaining = count content_items where embedded = false
if remaining > 0:
enqueue GenerateEmbeddingsJob // self-chain
log "Generated embeddings for {items.size} items ({remaining} remaining)"
The job queried for unembedded content items, sent them to OpenAI’s text-embedding-3-small model in a batch, stored the resulting vectors in the sqlite-vec virtual table, marked the items as embedded, and if there were more items remaining, enqueued another copy of itself.
This self-chaining pattern meant you could import 69,000 tweets and walk away. The jobs would keep running in the background, 50 at a time, until everything was embedded. I built a simple progress indicator that showed how many items remained so I could watch it chew through the backlog.
The EmbeddingService was a thin wrapper around the OpenAI API that handled both single embeddings (for user queries) and batch embeddings (for content ingestion):
class EmbeddingService:
MODEL = "text-embedding-3-small"
BATCH_SIZE = 100
function initialize():
this.client = new OpenAI_Client(api_key: env("OPENAI_API_KEY"))
function embed(text):
response = this.client.embeddings(model: MODEL, input: text)
return response.data[0].embedding
function embed_batch(texts):
results = []
for each batch in texts.each_slice(BATCH_SIZE):
response = this.client.embeddings(model: MODEL, input: batch)
sorted = response.data.sort_by(index)
results.append_all(sorted.map(d => d.embedding))
return results
I chose text-embedding-3-small over the larger model because the quality difference was marginal for this use case, and the smaller model was cheaper. At 1,536 dimensions (each piece of text gets represented as a list of 1,536 numbers) the vectors were detailed enough for semantic search without being wasteful.
Streaming responses
The first version of the chat returned the complete response all at once. You’d ask a question, stare at a typing indicator for several seconds, then get a wall of text. It worked, but the experience felt sluggish compared to ChatGPT or Claude’s interfaces where text streams in word by word.
Adding streaming required changes on both sides. On the backend, I needed the server to keep the HTTP connection open and send text to the browser as Claude generated it, piece by piece, rather than waiting for the full response. This is called Server-Sent Events (SSE), a protocol where the server pushes messages over a long-lived connection, and the browser reads them as they arrive. Most web frameworks support this through some form of streaming response, which lets a controller write to the response stream incrementally instead of building the entire response in memory first:
endpoint POST /chat:
question = request.body["question"].strip()
// Validation errors return JSON, not SSE
if question is blank:
set response content_type = "application/json"
write JSON { error: "Question is required" }
close stream
return
set response content_type = "text/event-stream"
set response cache_control = "no-cache"
set response header "X-Accel-Buffering" = "no"
service = new ChatService()
service.ask_streaming(question, on_event: function(event):
write to stream "data: " + JSON({ text: event.text }) + "\n\n"
)
write to stream "data: [DONE]\n\n"
on client disconnect:
// Client closed the connection — nothing to do
finally:
close stream
The streaming method on ChatService wrapped the Anthropic API’s native streaming support. The first version used a community SDK with a callback-style streaming parameter. Later I migrated to the official Anthropic SDK, which used a cleaner event-based streaming interface:
function ask_streaming(question, history = [], on_event):
search_query = reformulate_query(question, history)
query_embedding = embedding_service.embed(search_query)
results = ContentItem.search_similar(query_embedding, limit: 20)
results = rerank_by_recency(results)
context = build_context(results)
full_answer = ""
stream = anthropic.messages.stream(
model: "claude-sonnet-4-6",
system: SYSTEM_PROMPT,
messages: messages,
max_tokens: 1024
)
for each event in stream:
if event is text_event:
full_answer += event.text
on_event({ type: "text", text: event.text })
return full_answer
On the frontend, I used the Fetch API with a ReadableStream to consume the SSE data. Browsers have a built-in EventSource API designed for Server-Sent Events, but it only works with GET requests, and since I needed to POST the user’s question in the request body, I had to go the manual route. The JavaScript read chunks from the response stream, parsed out the SSE event data, accumulated the text, and re-rendered the message bubble after each chunk:
function streamChat(message, addMessageFn, hideTypingFn, scrollFn, onDone) {
fetch(CHAT_API_URL, {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ question: message })
})
.then(function(res) {
hideTypingFn();
// Validation errors come back as JSON, not SSE
var contentType = res.headers.get('content-type') || '';
if (contentType.indexOf('application/json') !== -1) {
return res.json().then(function(data) {
addMessageFn('<p>' + escapeHtml(data.error) + '</p>');
onDone();
});
}
var bubble = addMessageFn('');
var accumulated = '';
var reader = res.body.getReader();
var decoder = new TextDecoder();
var buffer = '';
function processChunk(result) {
if (result.done) {
bubble.innerHTML = formatAnswer(accumulated);
onDone();
return;
}
buffer += decoder.decode(result.value, { stream: true });
var lines = buffer.split('\n');
buffer = lines.pop();
for (var i = 0; i < lines.length; i++) {
var line = lines[i].trim();
if (!line.startsWith('data: ')) continue;
var payload = line.slice(6);
if (payload === '[DONE]') continue;
var parsed = JSON.parse(payload);
if (parsed.text) {
accumulated += parsed.text;
bubble.innerHTML = formatAnswer(accumulated);
scrollFn();
}
}
reader.read().then(processChunk);
}
reader.read().then(processChunk);
});
}
The result felt responsive: text started appearing within a second of submitting a question.
One subtlety: validation errors (empty question, question too long, no content available) still needed to return regular JSON responses, not SSE. The controller set the content type to application/json for these cases, and the frontend checked the content type header to decide whether to parse as JSON or read as a stream.
Conversation persistence
The website has two chat interfaces: a floating widget in the bottom-right corner and a full-page chat at /ask/. Clicking the expand button on the widget navigates to the full page. Initially, this wiped out the conversation. You’d start chatting in the widget, click expand, and land on a fresh page with no history.
The fix was sessionStorage. Every message (user and assistant) got saved to a chat_messages key as a JSON array. When either the widget or the ask page loaded, it checked for existing messages and replayed them into the DOM, replacing the default welcome message.
var CHAT_STORAGE_KEY = 'chat_messages';
function saveChatMessage(role, text) {
try {
var messages = JSON.parse(sessionStorage.getItem(CHAT_STORAGE_KEY) || '[]');
messages.push({ role: role, text: text });
sessionStorage.setItem(CHAT_STORAGE_KEY, JSON.stringify(messages));
} catch(e) { /* ignore storage errors */ }
}
function restoreChatMessages(containerId, addUserFn, addAssistantFn) {
var messages = JSON.parse(sessionStorage.getItem(CHAT_STORAGE_KEY) || '[]');
if (messages.length === 0) return false;
var container = document.getElementById(containerId);
container.innerHTML = '';
messages.forEach(function(msg) {
if (msg.role === 'user') addUserFn(msg.text);
else addAssistantFn(formatAnswer(msg.text));
});
return true;
}
Both interfaces called restoreChatMessages on page load:
restoreChatMessages('chatMessages', addUserMessage, addAssistantMessage);
restoreChatMessages('chatWidgetMessages', addWidgetUserMessage, addWidgetAssistantMessage);
The conversation persisted for the browser session and cleared when the tab was closed, which felt like the right balance between continuity and privacy.
The system prompt
Getting the system prompt right took several iterations. The first version had Claude respond in third person (“Edem thinks…”) which felt awkward and detached:
// Version 1: Third person, generic assistant
SYSTEM_PROMPT = """
You are Edem Kumodzi's AI assistant on his personal website.
You answer questions about Edem based on his tweets, blog posts,
and other content he has published over the years.
Keep responses concise but informative. Speak in third person
about Edem (e.g., "Edem thinks..." or "Based on his posts, Edem...").
"""
The second version had Claude respond as me, in first person, as if recalling my own thoughts and experiences:
// Version 2: First person, speaking as Edem
SYSTEM_PROMPT = """
You are Edem Kumodzi. You respond in first person as Edem
on his personal website. You have access to your own tweets,
blog posts, and other content you've published over the years.
Answer naturally and conversationally using the retrieved context.
Don't reference "my tweets" or "my blog posts" — just speak from
your perspective as if recalling your own thoughts and experiences.
"""
I also had to be explicit about topic boundaries. Without guardrails, the chatbot would happily answer questions about anything, hallucinating opinions I’ve never expressed. The prompt listed the seven topics I write about and instructed Claude to briefly decline anything outside those boundaries, suggesting the user reach out directly through my contact page.
One problem I ran into: when someone asked a vague question like “what can you help with?”, Claude would dump a formatted list of all seven topics with detailed descriptions. Not useful. Adding “Never list out all the topics you can discuss” to the prompt fixed that.
Recency bias
Pure cosine similarity (the vector distance measurement) has no concept of time. A tweet from 2011 and a blog post from last week are treated equally if their vectors are similar distances from the query. For a chatbot that was supposed to represent my current thinking, that was a problem. My views on software architecture have evolved over 15 years.
The fix was a gentle reranking step after the initial vector search. I fetched 20 candidates instead of 10, then applied a logarithmic time-decay penalty to each distance score before taking the top 10:
CANDIDATE_POOL_SIZE = 20
RECENCY_HALF_LIFE_DAYS = 730.0 // ~2 years
function rerank_by_recency(results):
return results.sort_by(result =>
item = result.content_item
age_days = if item.posted_at exists:
max((now - item.posted_at) in days, 0)
else:
365 * 15 // No date → assume very old
// ~0 days → 1.0x, ~2 yrs → ~1.15x, ~10 yrs → ~1.5x
result.distance * (1.0 + log(1.0 + age_days / RECENCY_HALF_LIFE_DAYS))
).first(MAX_CONTEXT_ITEMS)
The penalty was intentionally mild. A two-year-old post got only a ~15% distance increase. A ten-year-old tweet got ~50%. Semantic relevance still dominated — if an old tweet was a near-perfect match, it would still surface. But when two pieces of content were similarly relevant, the newer one won.
Follow-up questions and query reformulation
The first version of the chatbot was stateless: each question was embedded and searched independently. This broke down immediately with follow-up questions. If someone asked “What do you think about Ruby?” and then followed up with “What about its performance?”, the second question would search for content about generic performance, not Ruby’s performance.
The fix was query reformulation. Before embedding a follow-up question, I sent the conversation history to a fast, cheap model (Claude Haiku) with instructions to rewrite the question as a standalone query:
REFORMULATION_PROMPT = """
Rewrite the user's follow-up message as a single standalone question that
captures the full intent, incorporating any necessary context from the
conversation history. The rewritten question must be self-contained —
someone reading it with no prior context should understand exactly what
is being asked.
Return ONLY the rewritten question. No preamble, no explanation.
"""
function reformulate_query(question, history):
if history is empty:
return question
messages = []
for each turn in history:
messages.append({ role: "user", content: turn.question })
messages.append({ role: "assistant", content: turn.answer })
messages.append({ role: "user", content: question })
response = anthropic.messages.create(
model: "claude-haiku-4-5",
system: REFORMULATION_PROMPT,
messages: messages,
max_tokens: 256
)
reformulated = response.content.first.text
return reformulated if not blank, else question
on error:
log warning "Query reformulation failed"
return question // fall back to original
So “What about its performance?” became something like “What are Edem’s thoughts on Ruby’s performance characteristics?”, a query that retrieved useful context. The error handling ensured that if reformulation failed for any reason, the original question was used as a fallback. Claude Haiku was fast enough that the extra API call added negligible latency.
Taking it a step further
Once the chatbot could answer questions, I started wondering: what if it could also do things? The site already had a booking system, a calendar where visitors could schedule a paid 30-minute consultation. The entire flow existed as API endpoints: check available dates, check available time slots, create a booking, initiate payment. What if someone could just say “I’d like to book a time to chat” in the chatbot, and have it walk them through the whole process conversationally?
This is where tool use comes in. Modern LLMs like Claude don’t only generate text; you can give them a set of functions (called “tools”) that they’re allowed to invoke. You describe each tool’s name, purpose, and expected inputs, and the model decides when and whether to call one based on the conversation. When it does, instead of producing text, it produces a structured request: “I want to call get_available_dates with these parameters.” Your code executes the function, sends the result back, and the model continues from there — now with real data to work with.
I defined three booking tools that mapped directly onto existing backend logic:
{
"name": "get_available_dates",
"description": "Get dates that have available booking slots for a consultation.",
"input_schema": { "type": "object", "properties": {}, "required": [] }
}
{
"name": "get_available_times",
"description": "Get available time slots for a specific date.",
"input_schema": {
"type": "object",
"properties": {
"date": { "type": "string", "description": "The date to check (YYYY-MM-DD format)" }
},
"required": ["date"]
}
}
{
"name": "create_booking",
"description": "Create a booking for a consultation. For paid schedules, this initiates payment.",
"input_schema": {
"type": "object",
"properties": {
"slot_id": { "type": "integer", "description": "The slot ID from get_available_times results" },
"date": { "type": "string", "description": "The date of the slot (YYYY-MM-DD format)" },
"name": { "type": "string", "description": "The user's full name" },
"email": { "type": "string", "description": "The user's email address" },
"notes": { "type": "string", "description": "Optional notes about what they want to discuss" }
},
"required": ["slot_id", "date", "name", "email"]
}
}
Each tool’s execution method called the same models and logic that the regular booking API used. get_available_dates queried the Schedule model for dates with open slots. get_available_times returned the specific time slots for a given date. create_booking either confirmed a free booking immediately or created a Stripe Checkout Session for paid ones. No new business logic, a new interface to existing functionality.
The interesting part was the tool loop. A single user message like “I’d like to book a time” could trigger multiple tool calls within one response cycle. Claude would decide to call get_available_dates, receive the results, then stream a conversational message presenting the dates — all before the user said anything else. The code ran this as a loop with a safety cap of five iterations:
loop:
iterations += 1
break if iterations > MAX_TOOL_ITERATIONS
stream = anthropic.messages.stream(params with messages)
// Stream Claude's response, collecting any tool calls
tool_uses = []
for each event in stream:
if event is text_event:
on_event({ type: "text", text: event.text })
if event is tool_use_event:
tool_uses.append(extract_tool_use(event))
// If Claude didn't call any tools, we're done
break if tool_uses is empty
// Execute each tool and feed results back to Claude
for each tool_use in tool_uses:
result = execute_tool(tool_use.name, tool_use.input)
messages.append({
role: "user",
content: [{ type: "tool_result", tool_use_id: tool_use.id, content: result }]
})
From the user’s perspective, a full booking conversation looked something like this:
User: I’d like to book a time to chat with you.
Bot: I’d be happy to help you book a consultation! Let me check my availability… I have openings on Saturday, March 7th, and Sunday, March 8th. These are 30-minute sessions at $100. Which day works for you?
User: Saturday works.
Bot: Here are the available times on Saturday, March 7th: 9:00 AM, 9:30 AM, 10:00 AM, 10:30 AM… What time works best?
User: 10 AM. I’m John, john@example.com.
Bot: Let me book that for you…
At that point, the create_booking tool returned a checkout_required response with a Stripe session. The backend sent this to the frontend as a special action event in the SSE stream — alongside the regular text — and the frontend opened a Stripe Embedded Checkout overlay right inside the chat interface. After payment, the overlay closed and a confirmation card appeared in the conversation with the booking details.
The system prompt guided Claude through the flow step by step: present dates first, then times, then collect details one at a time. Getting this to feel natural took several iterations. The first version dumped all available dates and times at once, which was overwhelming. Refactoring it into a conversational back-and-forth, where Claude asked one question at a time and waited for the answer, made it feel much more like talking to a real person.
Tools turned the chatbot from a read-only Q&A system into something that could take actions on behalf of the user. The LLM handled the conversational complexity (understanding intent, asking clarifying questions, formatting dates) while the tools provided the structured interface to real backend functionality. Each piece stayed in its lane.
Once the tool infrastructure was in place, adding another tool was straightforward. The RAG chatbot had a blind spot: it could only draw from my own writing. If someone asked about a technology I’d mentioned in passing but never wrote about in depth, the retrieved context would be thin and the response would be vague or hedged. The fix was a web_search tool that let Claude search the internet for supplementary information when the local knowledge base wasn’t enough.
I used Tavily, a search API built for AI applications. It returns clean extracted text from web pages rather than raw HTML, which made the results usable as context for Claude. The tool definition was simple: take a search query, return up to five results with titles, snippets, and URLs.
{
"name": "web_search",
"description": "Search the internet for current information to supplement the retrieved context. Use when the context doesn't have enough information to answer well, or when the question requires recent or time-sensitive information.",
"input_schema": {
"type": "object",
"properties": {
"query": { "type": "string", "description": "The search query. Be specific and concise." }
},
"required": ["query"]
}
}
The execution method called a WebSearchService that handled the Tavily API call and tracked monthly usage against the free tier quota:
function execute_web_search(tool_input):
result = web_search_service.search(tool_input["query"], max_results: 5)
return JSON({
type: "web_search_results",
query: tool_input["query"],
results: result.results.map(r => {
title: r.title,
snippet: r.snippet truncated to 500 chars,
url: r.url
})
})
The key was the system prompt. Without guardrails, Claude would search the web for every question, even when my own writing had a perfectly good answer. The prompt instructions were explicit: only use web search when the retrieved context is insufficient, when the question is time-sensitive, or when it needs supplementary facts to round out an answer. For off-topic questions, the chatbot should still decline rather than search for unrelated information. When web results were used, Claude was instructed to weave them into the response alongside my own perspective, not dump a list of search results.
This turned the chatbot from a system that could only reference my past writing into one that could also stay current. If someone asked about a framework I’d tweeted about years ago, the response could combine my historical take with up-to-date information about where that framework is now.
What I learned
SQLite is more capable than people think. Between sqlite-vec for vector search, a SQLite-backed job queue for background jobs, and a SQLite-backed cache, I ran an entire production application on SQLite with no external dependencies. It won’t work for every use case, but for a single-instance personal site, it’s hard to beat the operational simplicity.
RAG is straightforward once you understand the pieces. The concept sounds complex (convert text into vectors, search by similarity, build a context window, generate a response) but each piece is simple in isolation. The hard part wasn’t the implementation; it was tuning the system prompt and chunk sizes to get useful responses.
Streaming makes a huge UX difference. The jump from “wait 5 seconds then show everything” to “text appears immediately, word by word” transformed the feel of the feature. It was the same response, but the perceived latency dropped dramatically.
Content quality matters more than quantity. 69,000 tweets sound impressive, but many were replies, retweets, or throwaway thoughts. The filtering step (removing retweets and short tweets) improved response quality. Chunking blog posts with title context produced much better search results than embedding entire posts.
Tools are a natural extension of a chatbot. Once the conversational interface existed, adding the ability to take actions (checking availability, creating bookings, initiating payments) was a matter of wrapping existing backend logic in tool definitions. The LLM handled the hard part: understanding intent and guiding the user through a multi-step process conversationally.
The final architecture
The stack with the chatbot and all its supporting pieces integrated:
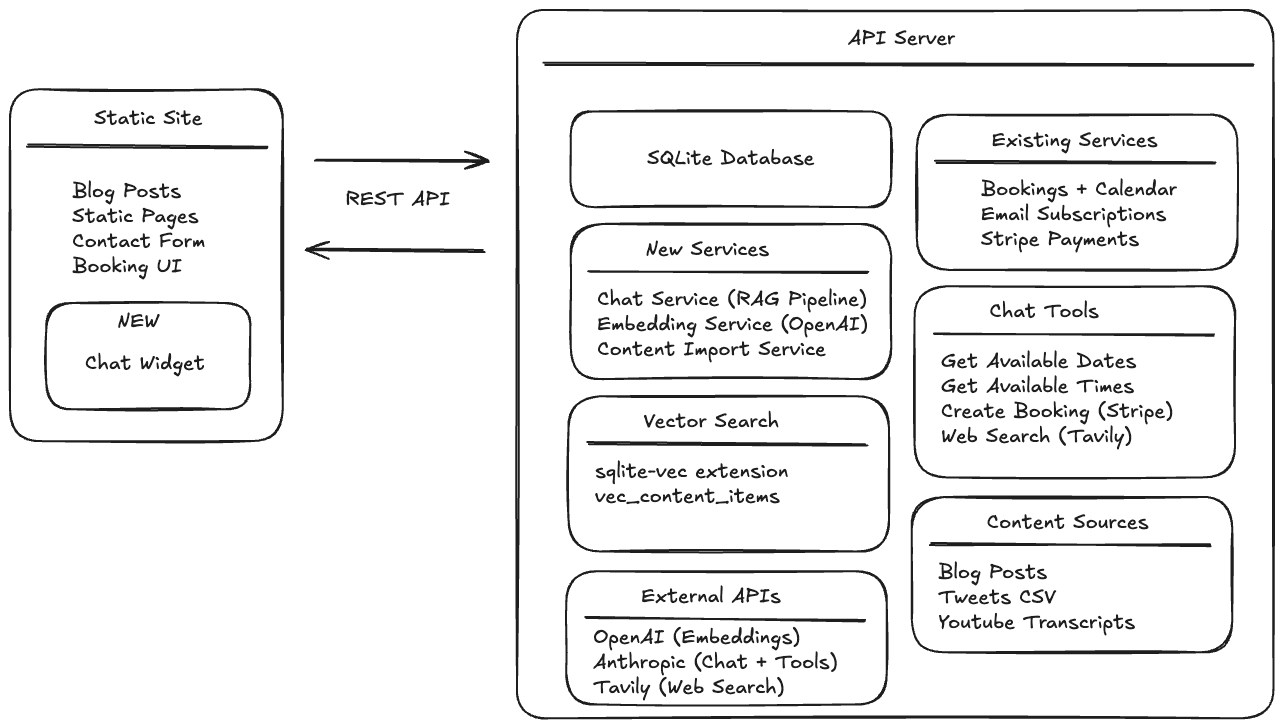
Compare this to the “before” diagram and the core architecture didn’t change. Still a single Docker container, still SQLite for everything, still continuous replication for backups. The chatbot added new services, background jobs, a sqlite-vec virtual table, booking tools, and external API integrations, but it all slotted into the existing structure. No new databases, no new infrastructure, no new deploy process. That was the whole point.
How I learn by building
This project is a good example of how I approach learning something new. I don’t start by reading the documentation cover to cover or taking a course. I start by defining a concrete outcome (in this case, a chatbot on my website that answers questions using my own writing) and then work backwards from that goal, learning enough about each piece to get a working solution.
The first version was rough. It returned responses in one big block instead of streaming them. The system prompt had Claude talking about me in the third person. Follow-up questions were broken because each query was stateless. But it worked. I could ask a question and get a grounded answer from my own content.
From that working baseline, every improvement was incremental. Streaming came next because the UX felt sluggish. The system prompt got rewritten because third person felt weird. Recency bias got added because ten-year-old tweets were drowning out recent blog posts. Query reformulation came last because follow-up questions were retrieving irrelevant context. Once all of that worked, the booking tools emerged from the conversational interface that was already there; extending it to take actions was a matter of defining functions and wiring them up. Web search followed the same pattern: once the tool loop existed, plugging in another tool to fill a gap in the knowledge base was a small addition. Each iteration solved a specific problem I could see and feel while using the thing.
This is the approach I’d recommend to anyone looking to learn a new technology: don’t try to understand the whole field first. Pick a project with a clear finish line, build the simplest version that crosses it, then iterate. You’ll learn more from debugging a broken streaming connection than from reading ten articles about Server-Sent Events.
The chatbot is live. Try it out: click the chat icon in the bottom-right corner, or visit the Ask Me Anything page. If it can’t answer your question, it’ll point you to my contact page so you can ask me directly.