Listen to this article (AI-generated narration)
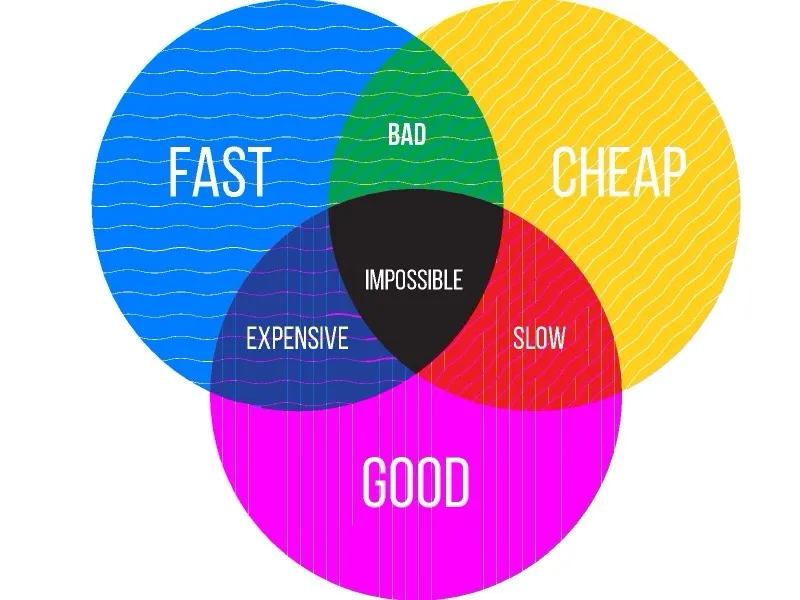 The Iron Triangle framed good, fast, and cheap as a three-way tradeoff.
The Iron Triangle framed good, fast, and cheap as a three-way tradeoff.
The first time the Iron Triangle stuck for me, I was in a product planning meeting with three bad options: cut scope, move the date, or spend more money. Someone used it to explain why the feature, the deadline, and the budget could not all survive unchanged.
Good, fast, cheap. Pick two. Good and fast means you pay. Fast and cheap means quality suffers. Good and cheap means you wait. It was shorthand, but it captured something true about software: you can compress a schedule, but the pressure goes somewhere. Scope shrinks, defects rise, budgets stretch, or engineers burn out.
The triangle was not a law of nature. It described an economic frontier: what a team could afford to build with the time, money, and tools available. AI-assisted engineering is starting to move that frontier, especially for teams building software the default ecosystem was never designed to serve.
How the triangle got here
The frontier has moved before.
 IBM System/360 Model 30 at the Computer History Museum. Photo: ArnoldReinhold, CC BY-SA 3.0.
IBM System/360 Model 30 at the Computer History Museum. Photo: ArnoldReinhold, CC BY-SA 3.0.
In the bespoke era, organizations paid for fit. Banks built banking systems. Airlines built reservation systems. Governments built record systems. The software matched the organization because the organization funded the whole thing. That gave teams control, but it made change slow and expensive.
 Software on a shelf at the Google NYC office computer museum. Photo: Marcin Wichary, CC BY 2.0.
Software on a shelf at the Google NYC office computer museum. Photo: Marcin Wichary, CC BY 2.0.
Shrinkwrap software changed the economics by making the product generic. A software company could build once and sell many times. Customers got word processors, spreadsheets, accounting packages, and databases without funding custom development. The fit became less specific, but the dependency stayed contained. If Microsoft Word 97 worked for your needs, it kept working until the machine died.
Open source and package registries made assembly normal. A small team could build a web application from frameworks, libraries, test runners, queue adapters, Markdown parsers, charting libraries, deployment tools, and database drivers written by strangers. A modern application contains a large amount of inherited labor.
 Slack’s pricing page circa 2015. Per user, per month, billed annually.
Slack’s pricing page circa 2015. Per user, per month, billed annually.
SaaS made the dependency active. You no longer installed software and left it alone. You subscribed to a service that kept changing. That gave teams speed, scale, and access to infrastructure they couldn’t build themselves. It also meant vendor roadmaps, API migrations, pricing changes, deprecations, and outages could become your work.
The industry’s answer was sensible: build your core problem well and outsource the rest. For many teams, that remains the right call. The problem starts when the thing you outsourced carries assumptions your users don’t share.
The old bargain
Imagine a fictional e-commerce startup called KayaCart. It sells household goods in Accra, Lagos, and Nairobi and relies on riders for last-mile delivery. The standard advice for a company like that is good advice: reuse what exists, compose from parts, don’t solve a solved problem.
If KayaCart is taking payments, the right answer is often Stripe or Paystack, not building its own payment processor. Authentication, email delivery, error tracking, customer support chat, analytics dashboards, billing portals, and feature flags all matter, but they are usually infrastructure around the product rather than the product itself.
Buying those pieces lets KayaCart ship something useful while the team is still small. It rents reliability before it can afford to hire for it. It inherits years of work from teams that solved the boring parts at a scale KayaCart has not reached. Modern startups exist because small teams can assemble powerful systems from mature services.
But buying software also means buying an opinion about how that software should work. The opinion shows up in the API, the data model, the dashboard, the pricing, the failure modes, the support process, the rate limits, the countries served, and the edge cases the vendor treats as normal.
At first, the fit looks close enough: the SDK works, the demo works, and KayaCart launches. Then real users arrive. A phone number parses wrong. WhatsApp works where SMS does not. An address does not resolve cleanly. Someone loses connectivity halfway through onboarding.
Each failure looks like a bug, so you patch it. You add fallbacks, lookup tables, retry jobs, manual review queues, provider-specific branches, and support macros. Every fix is reasonable in isolation because it is cheaper than replacing the dependency. Together, those fixes become an adapter layer.
Over time, that adapter becomes part of the product. Engineers translate between systems instead of shaping the product. The roadmap bends around vendor limits. Support learns the vendor’s failure modes. Finance learns the pricing cliffs. Users feel the seams.
For KayaCart, the mismatch becomes obvious in delivery. It can integrate Google Maps Platform or a similar mapping API, geocode an address, and send a rider to the pin. But many customers describe location by landmarks: “near the blue kiosk,” “behind the church,” or “call me when you reach the junction.” The API can provide a coordinate. The rider still needs context.
So KayaCart adds landmark fields, WhatsApp location sharing, rider call buttons, manual dispatch notes, and fallback instructions. Those features were not the original product, but they become part of how delivery succeeds. The customer does not see an abstraction mismatch. They see a late order, a confused rider, or a package sent to the wrong place.
Adapter debt in practice
None of this is technical debt in the usual sense. KayaCart did not start with a bad internal abstraction; it inherited a model of the world that did not fit its users. Technical debt usually starts inside your system: a shortcut, a rushed abstraction, or a once-reasonable decision that later charges interest. Adapter debt starts at the boundary between your product and someone else’s abstraction. You can see it in three places.
Semantic debt appears when the vendor’s nouns don’t match yours. KayaCart has riders, delivery attempts, landmarks, and customer instructions. A vendor might have drivers, tasks, addresses, and messages. Engineers spend years translating between concepts that should have been first-class in the product. Users feel it when a form asks for fields that don’t make sense or an error message hides the real reason something failed.
Economic debt appears when the vendor’s pricing punishes your use case. Per-message pricing hurts KayaCart when carrier failures force retries. Per-lookup pricing hurts when address search fails and riders need repeated corrections. Per-seat pricing hurts when users are seasonal, shared, or informal. The feature may work while the unit economics deteriorate.
Operational debt appears when the vendor’s failures become your support burden. Their delayed webhook becomes KayaCart’s reconciliation job. Their outage becomes its incident. Their support SLA becomes its customer experience. It also shows up when the roadmap waits on someone else’s priorities: a country, a permission model, a data export, or offline support that the vendor doesn’t plan to build.
Adapter debt isn’t bad by default. Sometimes it buys speed, and taking it on is the right decision. The mistake is failing to price it.
Buy has a shelf life
Software teams spent decades trying to move faster without sacrificing quality or blowing up cost. Agile shortened feedback loops. DevOps closed the gap between building software and running it. Continuous delivery made releases smaller and failures cheaper.
These movements mattered. They made teams better and reduced waste around the work. They did not remove the engineering work itself. Someone still had to build the feature, test the edge cases, and carry the architecture forward. As long as that work stayed expensive, buying remained the rational starting point for many teams.
Buying is often right in year one and wrong in year four. Dropbox started on AWS S3 because building storage infrastructure would have been absurd for a young startup. S3 worked and scaled, but Dropbox eventually reached hundreds of petabytes and the economics changed. The company spent years building Magic Pocket, a storage system designed for its own access patterns and cost structure. S3 was appropriate at the start; later, the company had good reasons to own storage.
Most companies won’t reach Dropbox scale, but the same timing problem shows up much earlier: a dependency can be the right answer until its assumptions cost more than ownership.
Build versus buy has no permanent answer. The right answer depends on timing, scale, context, and the cost of the adapter layer. This is where AI-assisted engineering enters.
How AI moves the threshold
The ownership shift often starts small. A team buys a third-party tool because buying is faster than building. Then, once the shape of the problem is clear, it replaces the narrow slice that matters most: a reporting layer, an operations console, a routing system, a billing workflow, a data export pipeline. The goal is not to rebuild the whole vendor. It is to own the part where the vendor’s abstraction is costing money, support time, or product quality.
Dropbox is the extreme version of that move. Most teams face smaller choices much earlier. AI-assisted engineering changes those choices by lowering the cost of the scaffolding around context-specific software: HTTP clients, queue workers, admin screens, retry logic, migrations, fixtures, documentation, and tests.
The useful version is not magic, and it is not a replacement for engineering judgment. The engineer still defines the domain rules, reviews the code, runs the tests, checks the edge cases, and owns the result.
Consider KayaCart’s reporting problem. The buy decision is obvious: plug in a tool like Looker, Power BI, or Metabase and let operations explore the data. Those tools are excellent when the questions match the shape of the data.
In production, the questions get more specific. Which locations produce the most orders? Which neighborhoods should get more riders? Which delivery zones deserve a local warehouse? A reporting tool can chart orders and revenue, but it cannot tell KayaCart that “behind school junction” and “right in front of school junction” may describe the same place, especially when neither phrase resolves to a useful GPS coordinate.
KayaCart starts building the missing location model around the reporting tool: manual address tagging, landmark dictionaries, normalized delivery zones, review queues, and data jobs that group messy customer descriptions into places the business can reason about. The reporting tool remains useful, but the real system is the location abstraction KayaCart built around it.
AI changes the cost of testing whether KayaCart should own that location model. A senior engineer can take a month of order addresses and use AI to draft an importer, a normalized-location table, a review screen, and tests for the awkward cases: two phrases that name the same junction, a landmark with no usable coordinate, and a customer description that points to the wrong compound. The engineer still decides how locations should be grouped, which matches require human review, which numbers operations can trust, and how the model should feed dispatch, warehousing, and reporting.
If the spike fails, the team learns before replacing the tool. If it works, operational knowledge moves out of scattered dashboards and spreadsheets and into a cleaner internal abstraction. Engineers spend less time writing boilerplate and more time modeling the actual constraints.
The same logic applies to other context-heavy systems: offline rider workflows, refund queues, fraud review screens, and compliance reports. They may sit outside the core product, but they shape how quickly the company can respond when users get stuck. AI lowers the cost to prototype, test, and own them.
The new build-versus-buy question
The old question was: is this our core competency? That still matters, but it is not enough. A system can sit outside your core competency and still shape the user experience. Bad reporting can hide delivery failures. Bad addressing can make orders impossible. Bad payment or fraud checks can reject legitimate customers.
The better question is: does context-fit matter enough here that we should own the abstraction?
Buy when:
- The vendor’s assumptions match your users
- The problem is regulated or security-sensitive, and the vendor is better equipped to own it
- You need speed to learn whether the product should exist
- Your team doesn’t understand the domain well enough yet
- The integration is shallow and easy to replace
Build when:
- Adapter debt consumes product work
- Vendor pricing punishes your specific user behavior
- Users can see the abstraction mismatch
- The vendor’s roadmap blocks yours
- Owning the abstraction would make future work simpler
Use AI when:
- The blocker is engineering throughput, not missing domain knowledge
- The work has common scaffolding around a context-specific core
- Your team can review, test, deploy, monitor, and maintain the result
AI should lower the cost of the right ownership. It should not tempt you into owning everything.
The hard parts remain
Some things should stay bought, borrowed, or built with extreme care. Don’t build your own cryptography because AI can generate AES wrappers. Don’t build your own database because an agent can scaffold a storage engine. Don’t build your own payment processor because a checkout integration annoyed you.
Compliance deserves the same caution. If you don’t understand the law, the audit, and the consequences of being wrong, code generation will not save you. AI can make bad decisions cheaper to execute without making them better decisions.
Generated code still has to run in production. Incidents, migrations, support, security, monitoring, and the edge case that shows up once a month and blocks revenue remain human obligations. A system that takes two weeks to generate can still take years to own.
AI can reduce the cost of producing code. It cannot erase the cost of owning behavior. If KayaCart’s generated dispatch tool sends riders to the wrong place, the customer doesn’t care that the first version came from an agent. If its offline sync layer loses data, the user doesn’t care that the conflict resolver passed the tests the model wrote.
AI makes code cheaper, not the commitment behind it. Its best use gives engineers more room to apply judgment.
The triangle, revisited
I keep thinking about that planning meeting. Good, fast, cheap. Pick two. The tradeoff still exists. You can’t prompt your way out of complexity or avoid responsibility by generating code faster. Durable systems still need judgment, taste, discipline, and care.
The triangle did not describe fixed laws. It described what teams could afford at a given moment.
For decades, software tools made parts of the job cheaper. Higher-level languages, frameworks, open source, cloud, SaaS, Agile, and DevOps all reduced friction around the work. AI-assisted engineering reaches a deeper bottleneck: the cost of producing custom software.
The teams most underserved by default abstractions will feel that change first. They can reconsider tools they tolerated because building the right thing once felt too expensive.
More things are worth building yourself than before. Good, fast, and cheap are still in tension, but the frontier has moved. More teams can now get closer to all three when they own the software their users need.